Tema 3: Análisis sintáctico - Ejercicios de modelado LL(1) y RLL(1)
Solución del control de análisis sintáctico del grupo TE2 del curso 2007/2008
Aquí se reproduce solamente una solución del primer apartado de cada tipo y se indican algunos errores que hay que evitar.
Solución A (0.25 puntos)
La gramática G1 podría ser la siguiente:
<Linea> -> <Asignación> salto | <Escritura> salto
<Asignación> -> id (coma <Asignación> coma <Expresión> | asigna <Expresión>)
<Escritura> -> muestra <Expresión>
<Expresión> -> <Término> (suma <Término>)*
<Término> -> <Factor> (pot <Término>)?
<Factor> -> id | entero | apar <Expresión> cpar
Para entender cómo se ha modelado la asignación, véase este ejercicio M1 (en el que se pueden encontrar ideas para otras soluciones).
Eliminando partes derechas regulares obtenemos G2:
<Linea> -> <Asignación> salto | <Escritura> salto
<Asignación> -> id <Asignación2>
<Asignación2> -> coma <Asignación> coma <Expresión> | asigna <Expresión>
<Escritura> -> muestra <Expresión>
<Expresión> -> <Término> <MasTérminos>
<MasTérminos> -> suma <Término> <MasTérminos> | 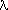
<Término> -> <Factor> <Exponente>
<Exponente> -> pot <Término> |
<Factor> -> id | entero | apar <Expresión> cpar
Solución B (0.20 puntos)
Una alternativa que no tuviese en cuenta la restricción sobre el
número de expresiones en la asignación podría ser:
<Linea> -> <Asignación> salto | <Escritura> salto
<Asignación> -> id (coma id)* asigna <Expresión> (coma <Expresión>)*
<Escritura> -> muestra <Expresión>
<Expresión> -> <Término> (suma <Término>)*
<Término> -> <Factor> (pot <Término>)?
<Factor> -> id | entero | apar <Expresión> cpar
Considerando conjuntamente los niveles sintáctico y semántico, esta es la solución más natural y aconsejable, dejando que sea posteriormente el nivel semántico el que verifique que a cada identificador a la izquierda de la asignación le corresponde una expresión a la derecha. Pero en esta prueba, como ejercicio de modelado y al igual que en algunos de los ejercicios previos, se pedía y valoraba más la solución A.
Eliminando partes derechas regulares obtenemos:
<Linea> -> <Asignación> salto | <Escritura> salto
<Asignación> -> id <MasIds> asigna <Expresión> <MasExpresiónes>
<MasIds> -> coma id <MasIds> |
<MasExpresiónes> -> coma <Expresión> <MasExpresiónes> |
<Escritura> -> muestra <Expresión>
<Expresión> -> <Término> <MasTérminos>
<MasTérminos> -> suma <Término> <MasTérminos> |
<Término> -> <Factor> <Exponente>
<Exponente> -> pot <Término> |
<Factor> -> id | entero | apar <Expresión> cpar
Ejemplos de errores
Esto que sigue son ejemplos de producciones incorrectas porque la
gramática G1 así no sería RLL(1), aunque sean similares a
las anteriores:
<Asignación> -> id coma <Asignación>
coma <Expresión> | id asigna <Expresión>
<Asignación> -> (id coma)* id asigna <Expresión> (coma <Expresión>)*
<Asignación> -> id (coma id)* asigna (<Expresión> coma)* <Expresión>
<Asignación> -> (id coma)* id asigna (<Expresión> coma)* <Expresión>
<Expresión> -> (<Término> suma)* <Término>
<Expresión> -> <Expresión> suma <Término> | <Término>
<Término> -> <Factor> pot <Término> | <Factor>
En este tema debes llegar a tener la experiencia necesaria para detectar eso y evitarlo, sin necesitar rellenar la tabla de análisis para verlo.