Redes neuronales convolucionales
Introducción
La visión por computador es una disciplina con una gran trayectoria en las Ciencias de la Computación.

Introducción
Las redes neuronales convolucionales están inspiradas en el funcionamiento de la percepción de la visión:
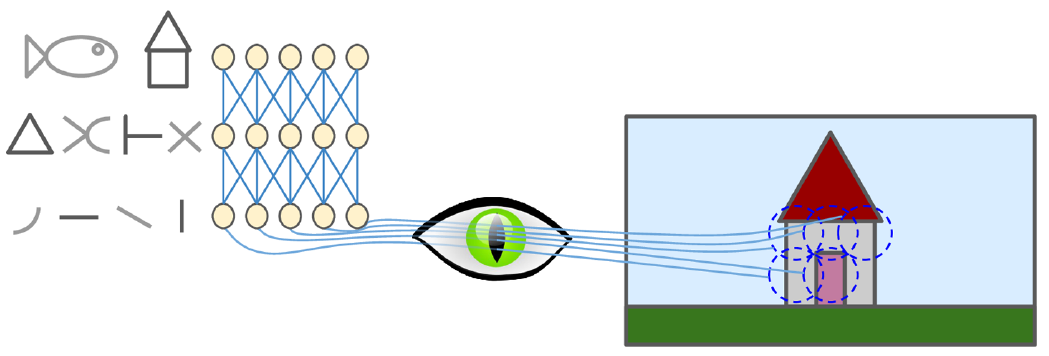
Clasificación
Un modelo de clasificación está entrenado de tal modo que es capaz de asignar una clase, o etiqueta, a una nueva muestra.
Perro 
Gato 
Ubicación
Encontrar la caja delimitadora de un objeto dentro de una imagen:

Detección de objetos
Encontrar todos los objetos dentro de una imagen:

Segmentación semántica
Asigna cada pixel a uno de los objetos detectados.

Convoluciones
Una convolución es una operación entre los píxeles de una imagen. En estos dos casos, el paso es de 1 pixel. La figura de la derecha muestra la opción con márgenes añadidos.
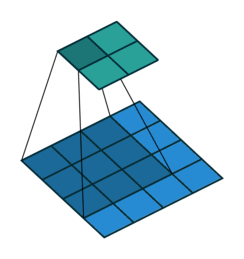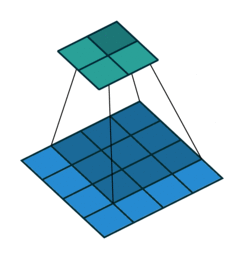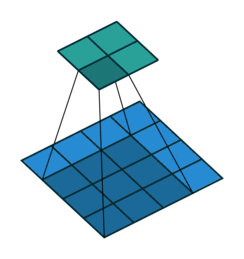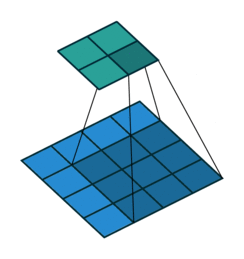
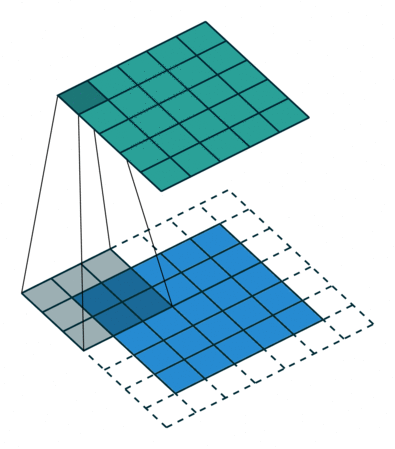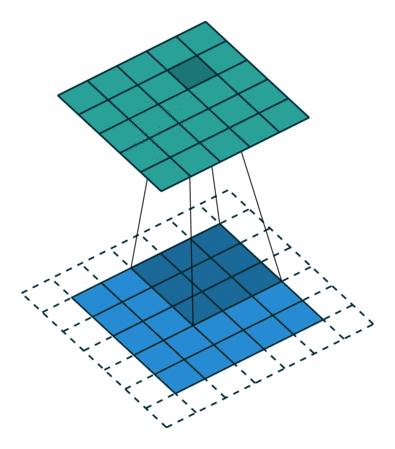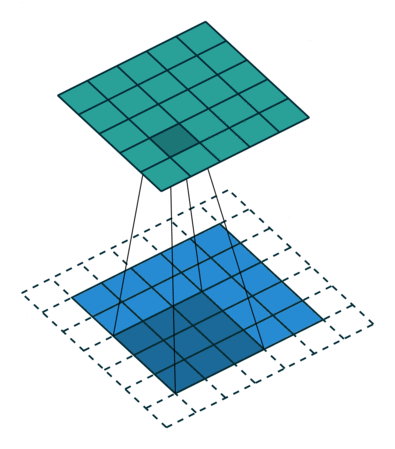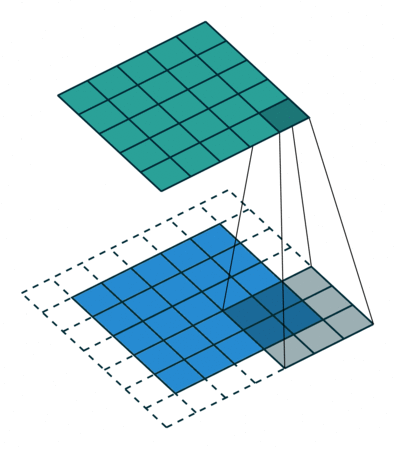
Convoluciones
En este otro caso, el paso es de 2 píxeles.
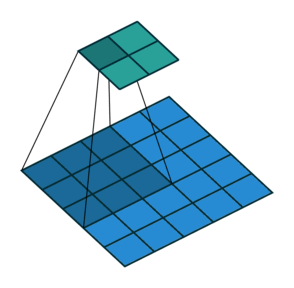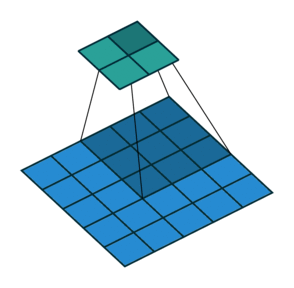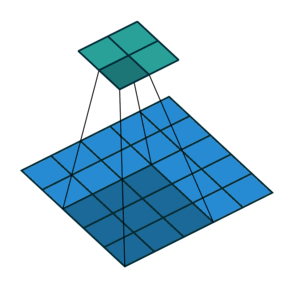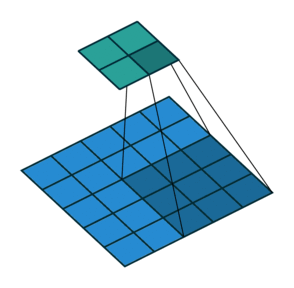
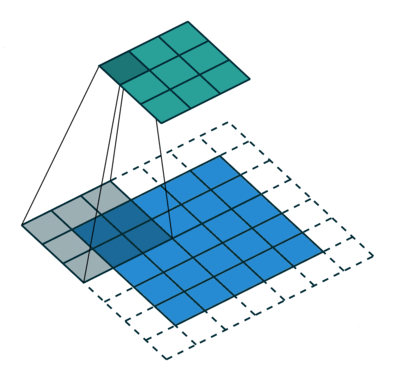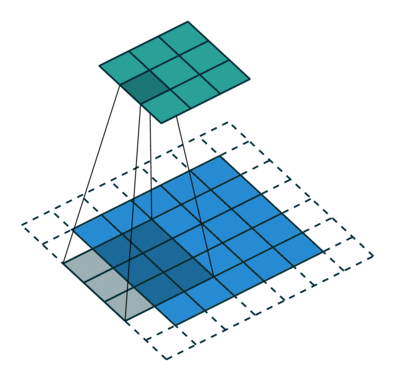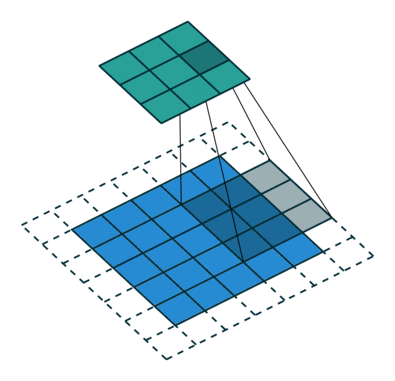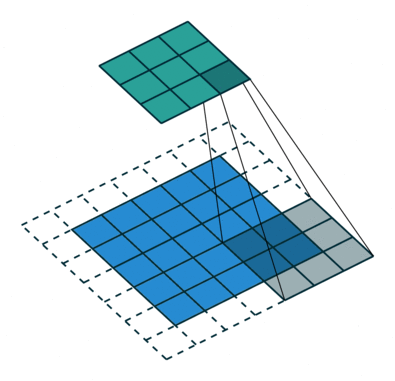
Convoluciones
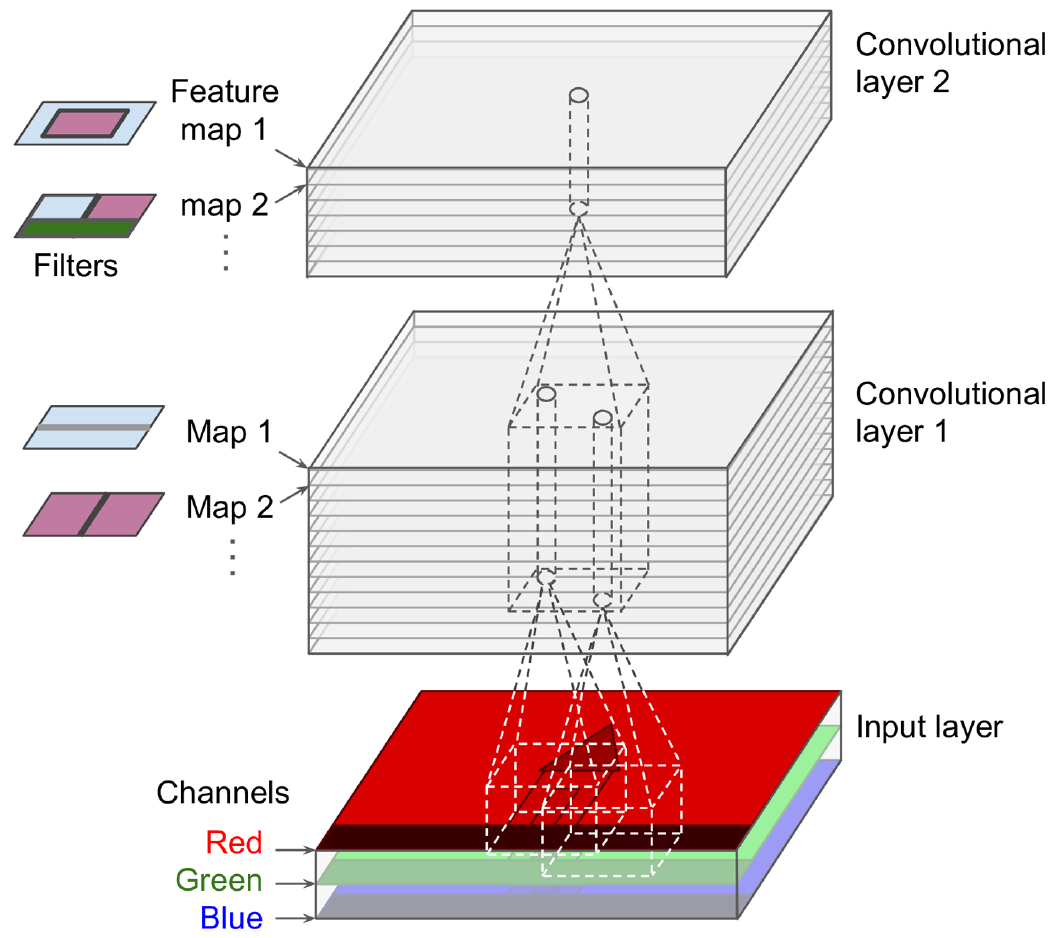
Las imágenes en color tienen tres canales: rojo, verde y azul. Las convoluciones pueden ser distintas para cada uno de los canales.

Convoluciones
Ejemplo de convolución que emborrona una imagen:
\[ \begin{equation} \frac{1}{9} \begin{bmatrix} 1 & 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \\ \end{bmatrix} \end{equation} \]


Convoluciones
Ejemplo de convolución que resalta los bordes:
\[ \begin{equation} \frac{1}{9} \begin{bmatrix} 0 & -1 & 0 \\ -1 & 4 & -1 \\ 0 & -1 & 0 \\ \end{bmatrix} \end{equation} \]

Show me the code
Para instanciar una capa convolucional en Keras:
tf.keras.layers.Conv2D(6,
kernel_size=(5, 5),
strides=(1, 1),
activation='tanh',
input_shape=[28, 28, 1],
padding="same")- El primer número 6 indica el número de subcapas de convolución.
Show me the code
- padding: se añaden píxeles nulos para que la imagen de la salida sea \(ancho_{entrada}/salto\).
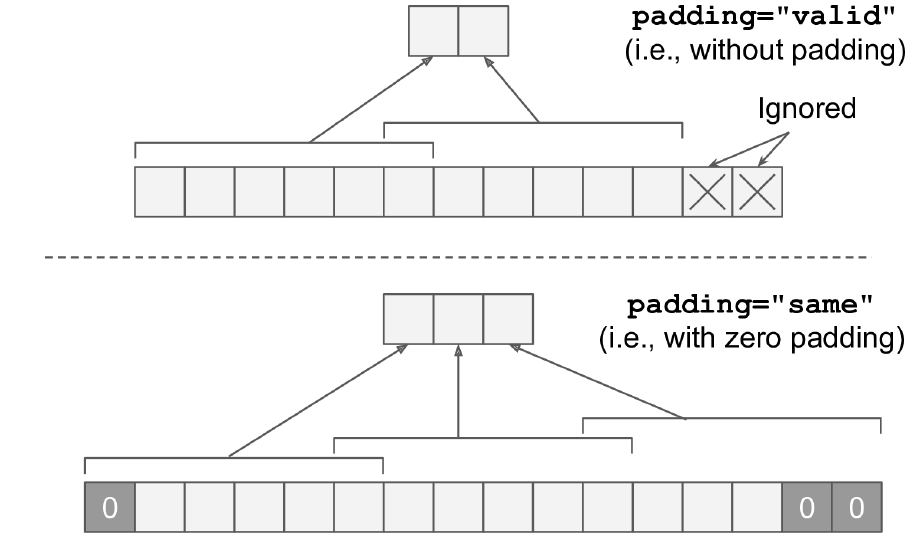
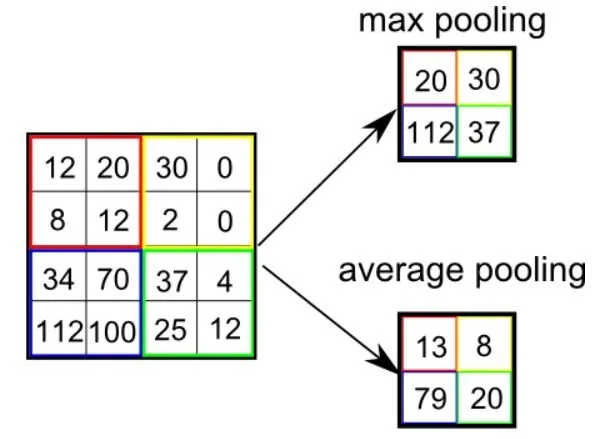
Pooling
El número de parámetros que hay que entrenar crece al aplicar capas de convoluciones. Una manera de reducir el número de parámetros es aplicar capas de pooling:
Arquitectura básica de una CNN
Esta es la arquitectura básica de una CNN. Observa cómo se van alternando las capas convolucionales con las capas de pooling.
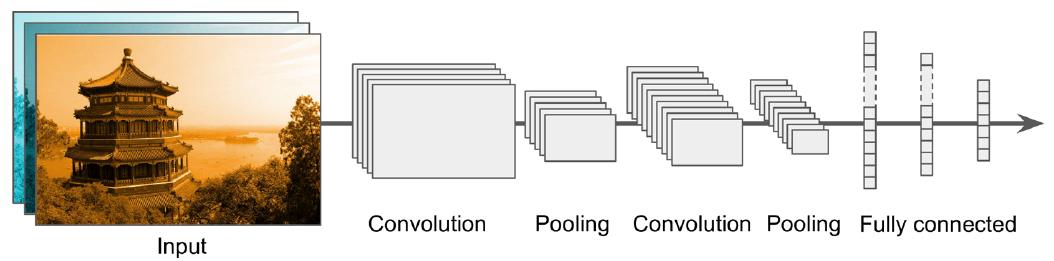
Al final hay una estructura de capas totalmente conectadas.
LeNet5
Esta es la arquitectura original presentada por Yann Le-Cunn et al.
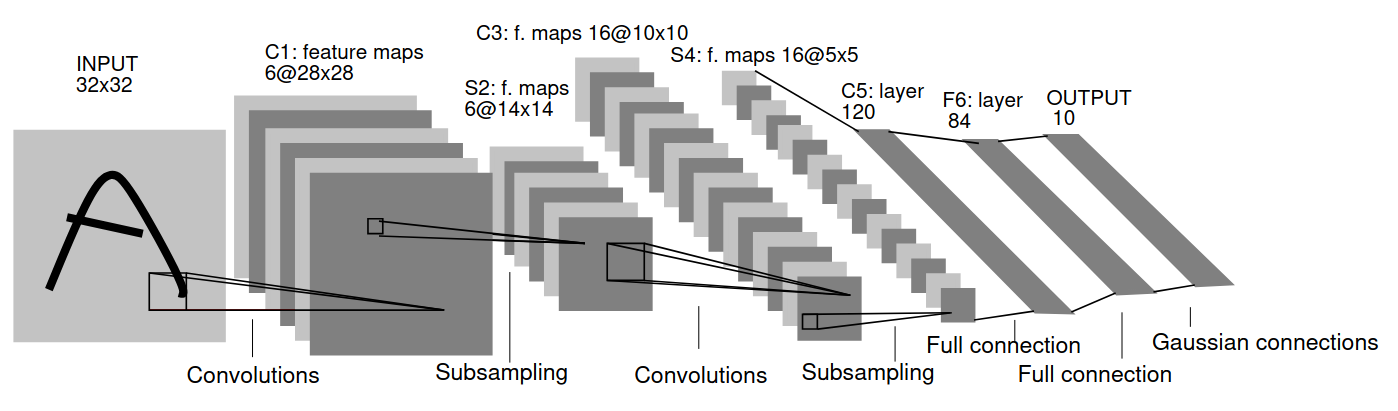
Las Gaussian connections del final son la activación softmax.
LeNet5
MINIST es el conjunto con el que se entrenó LeNet5:

LeNet5
Si entrenamos LeNet5 con el conjunto MNIST, utilizando como función de activación la función tanh y como optimizador Stocastic Gradient Descent (SGD), durante 20 épocas, obtenemos una precisión sobre el conjunto de pruebas del 98%!!!.
Historia 
Matriz de confusión 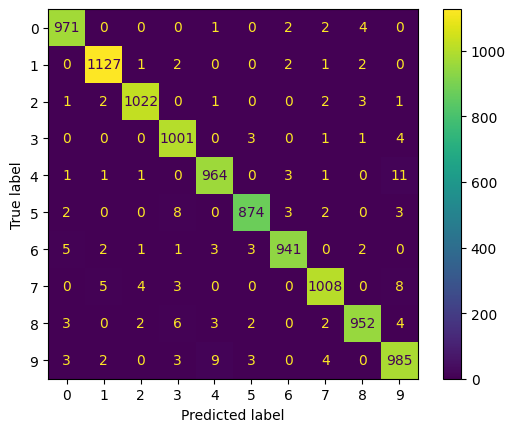
LeNet5
Si utilizamos como función de activación la función relu y como optimizador Adam, durante 20 épocas, obtenemos una precisión sobre el conjunto de pruebas de casi el 99%.
Historia 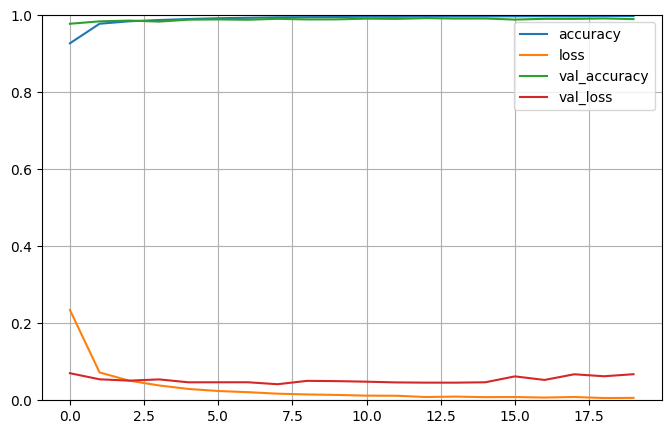
Matriz de confusión 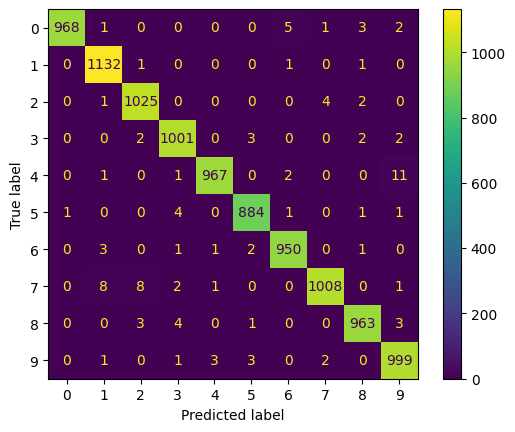
LeNet5
Aquí puedes comparar el desempeño de ambas implementaciones:
Tanh + sgd (precisión: 98%)
ReLu + Adam (precision: 99%)
LeNet5
Algunos ejemplos:
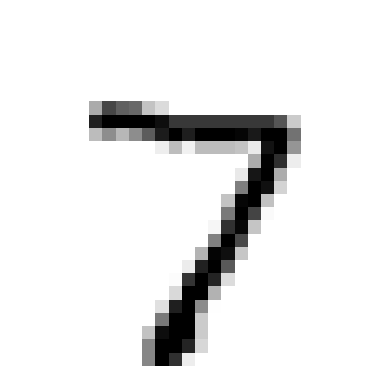
[1.0795905e-19 5.6615489e-12 1.5740088e-13 8.3432508e-14 8.5658287e-16 9.8535682e-16 3.1860348e-19 1.0000000e+00 1.1258355e-17 3.4307670e-12]
LeNet5
Algunos ejemplos:
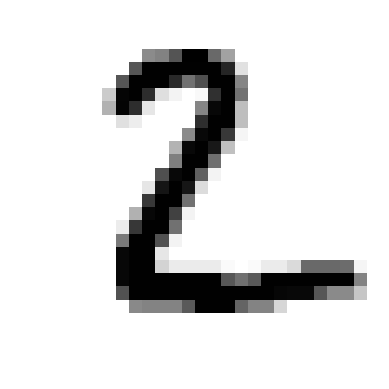
[3.57783143e-16 4.28349088e-13 1.00000000e+00 1.95093300e-16 8.98499199e-17 1.41323059e-23 1.89028567e-12 1.19629157e-14 2.68268784e-17 1.12507135e-17]
LeNet5
Podemos probar con un conjunto de datos más difícil Fashion MNIST, que tiene el mismo número de imágenes que MNIST, pero esta vez de objetos más complejos, ropa y complementos (10 clases).
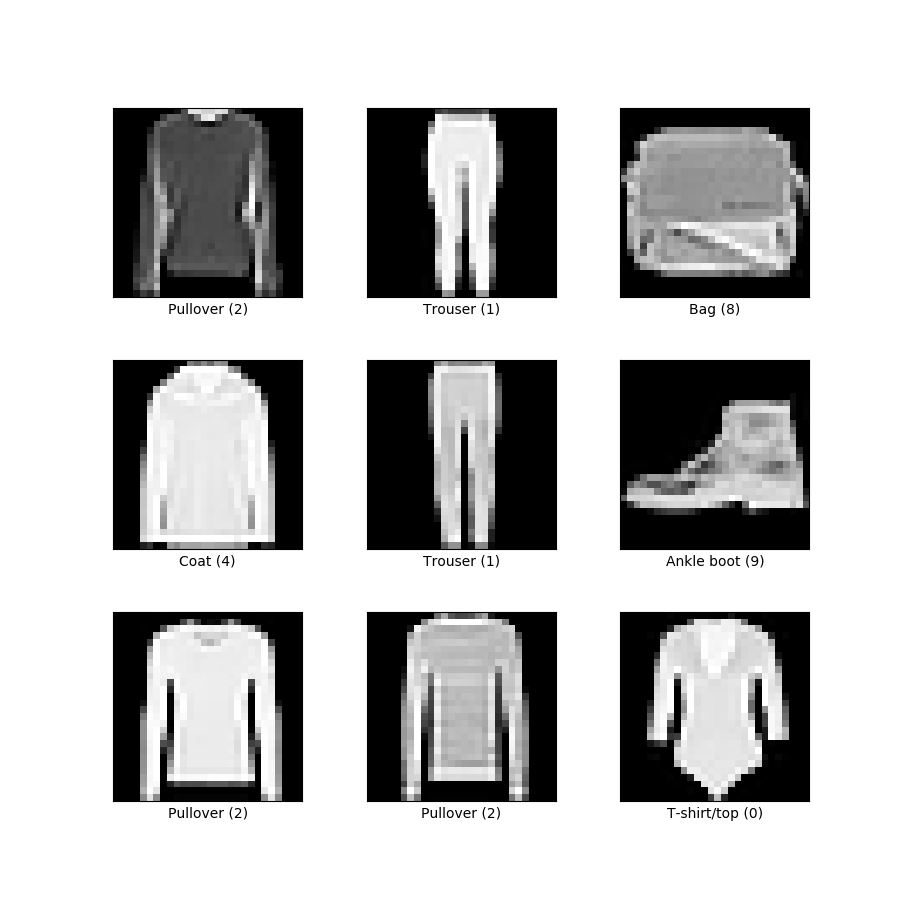
LeNet5
La historia del entrenamiento y la matriz de confusión:
Tanh + sgd (precisión: 88%) 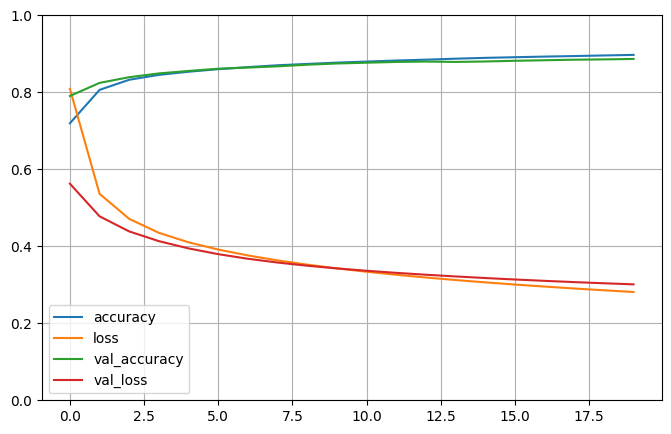
Matriz de confusión 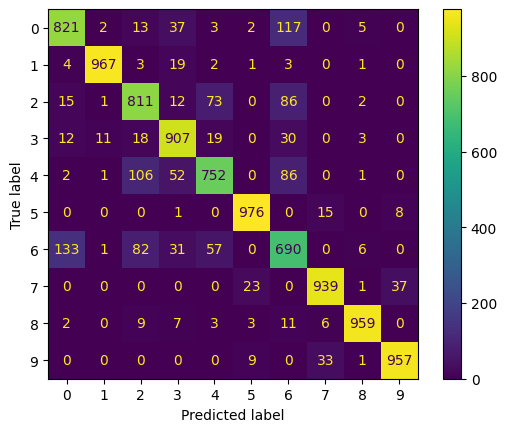
ResNet
ResNet introdujo una novedad en su diseño para reducir el problema del desvanecimiento del gradiente. La novedad es en saltar capas:
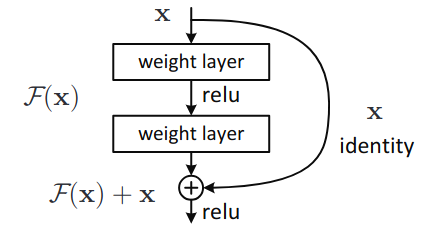
\[ H(x) = F(x) + x \rightarrow F(x) = H(x) - x \]
ResNet
Lo que aprenden las dos capas intermedias de la figura (representadas por la función \(F(x)\)) es a ajustar la diferencia entre la entrada real a la capa y el resultado de la aplicación de la capa.
YOLO
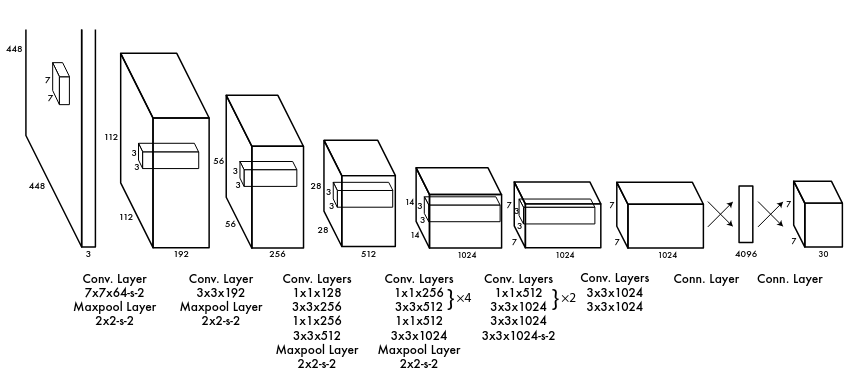
Y esta es la arquitectura tal y como se presenta en el artículo:
Show me the code
Para comparar las prestaciones de cada modelo, vamos a empezar con el de menor tamaño, 2.6 millones de parámetros y tarea de detección:
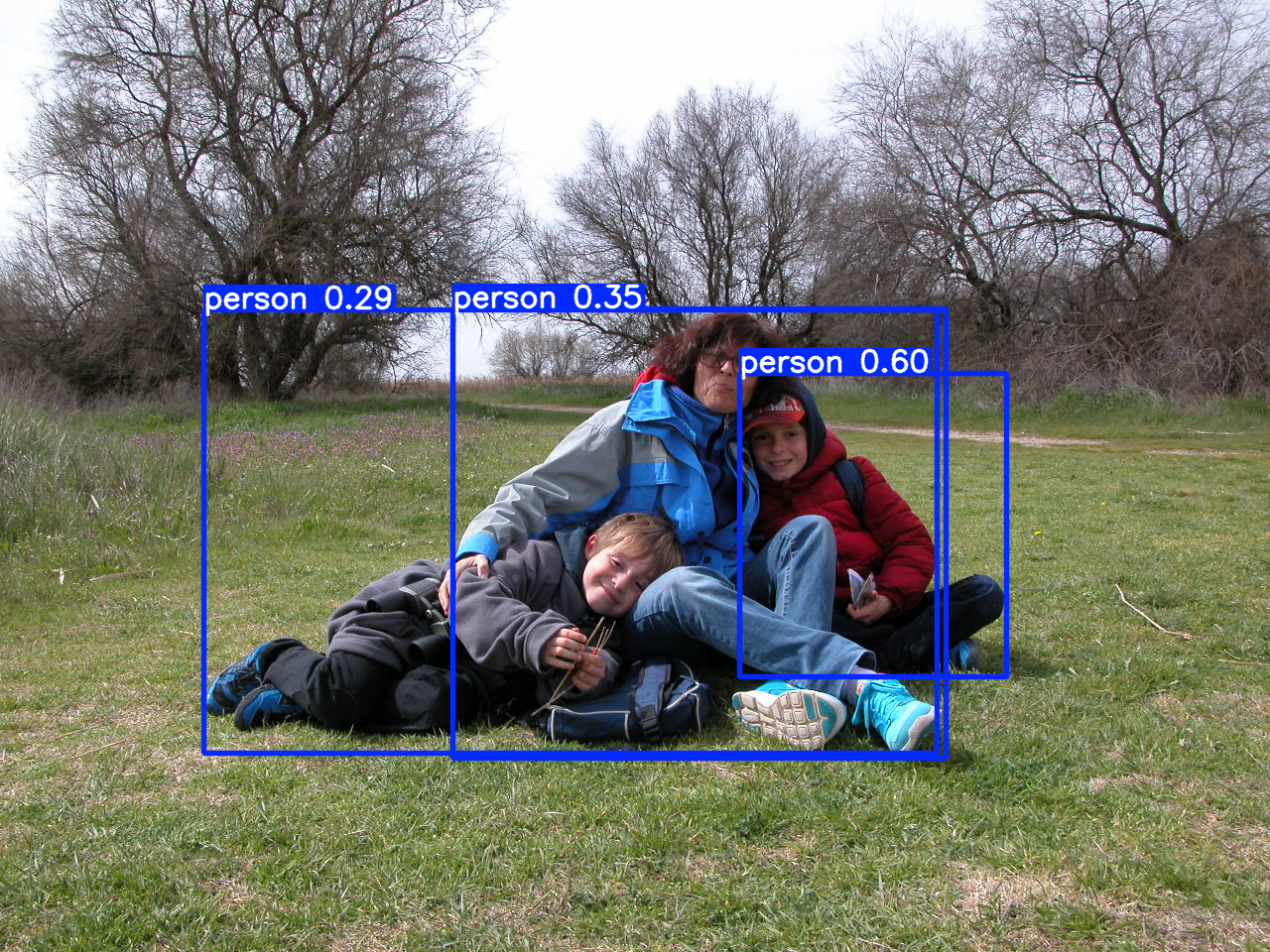
Show me the code
Veamos ahora con el mayor modelo, 56.9 millones de parámetros
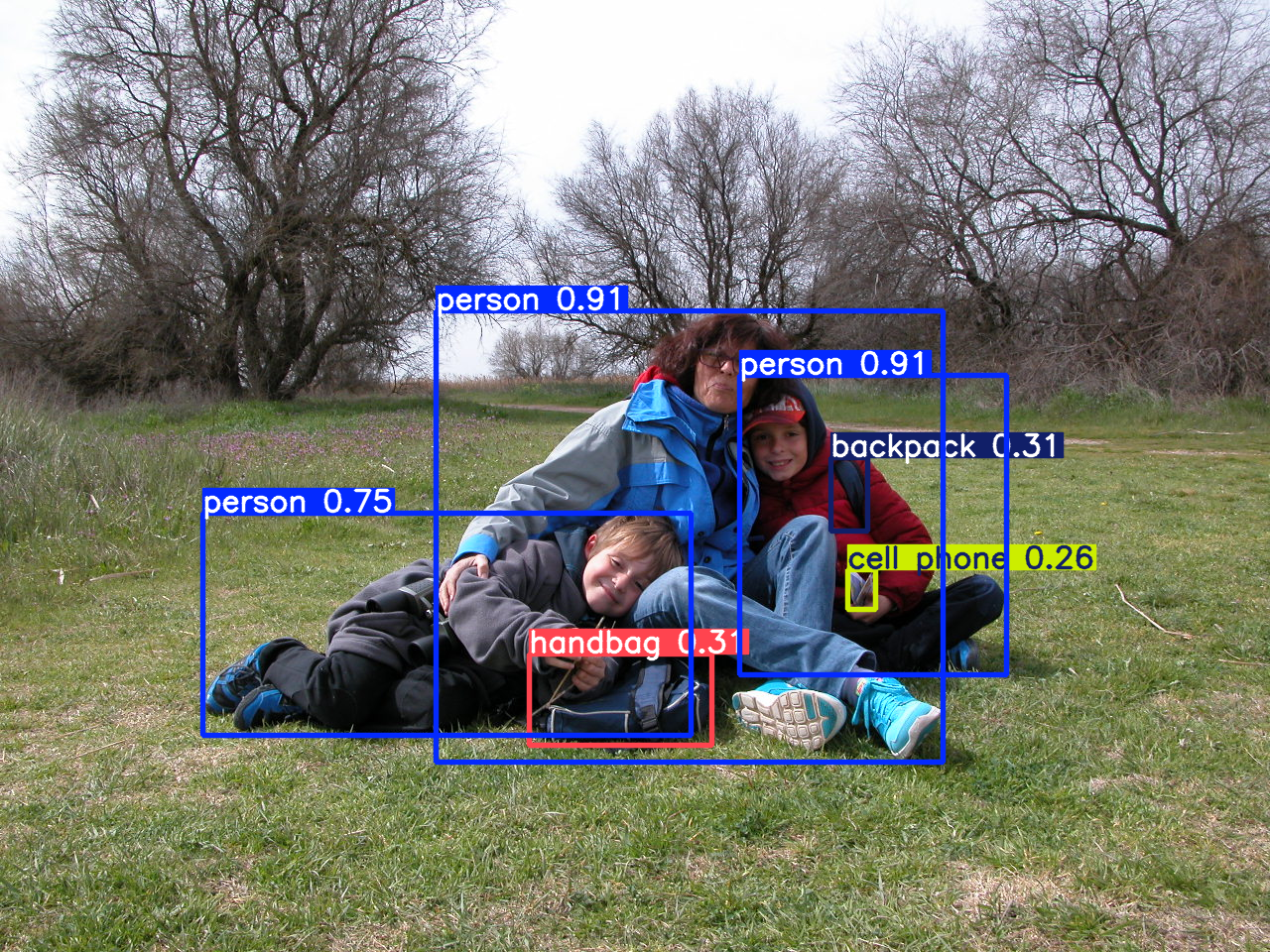
Show me the code
Pasemos ahora a la segmentación semántica, lo único que tenemos que hacer es cambiar el modelo, el resto de código es el mismo:

Show me the code
Con el modelo más grande para segmentación:
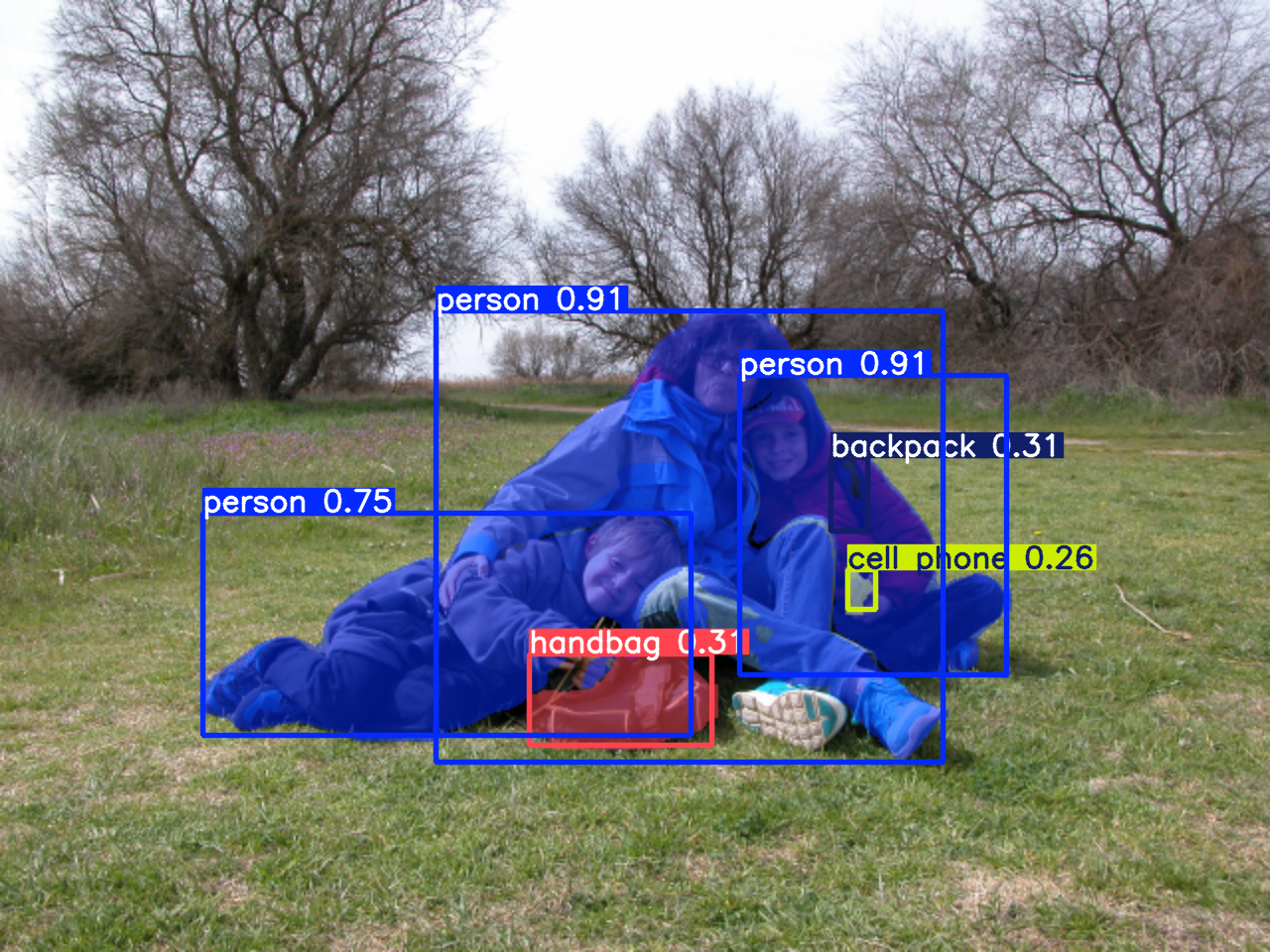
Show me the code
YOLO también es capaz de encontrar el esqueleto:
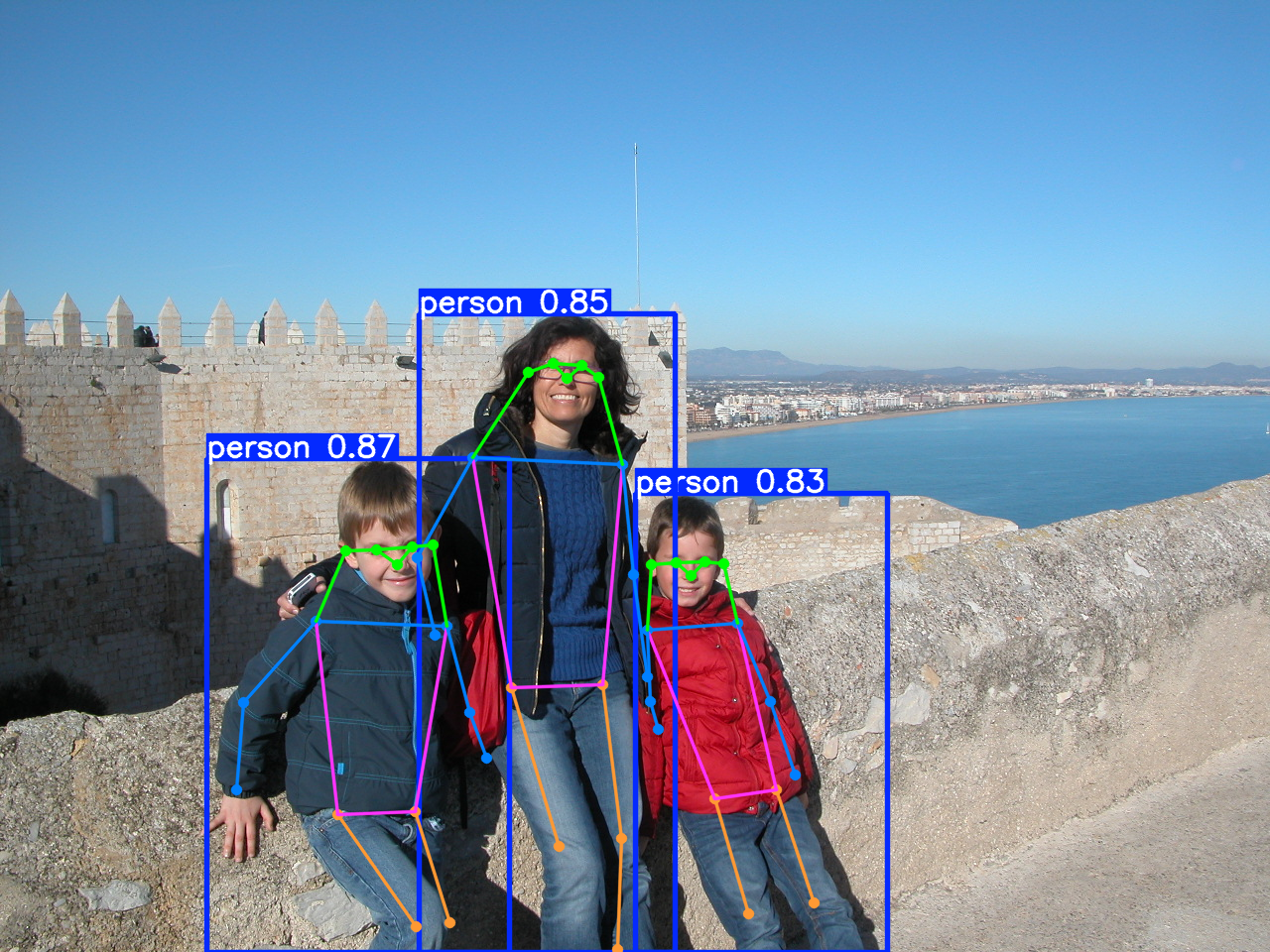
Transferencia de aprendizaje con YOLO
Ultralytics espera la siguiente estructura en los datos de entrenamiento:
Show me the result
Este es un ejemplo del trabajo de Arturo, estudiante de máster:

Recursos
- A Comprehensive Guide to Convolutional Neural Networks.
- You Only Look Once - YOLO.
- Ejemplo completo de transferencia de aprendizaje.
