El Procesamiento del Lenguaje Natural (PLN, NLP - Natural Language Processing) es un campo de la inteligencia artificial que se ocupa del estudio y desarrollo de algoritmos y modelos capaces de analizar, generar y transformar el lenguaje humano en forma escrita o hablada.
Su objetivo principal es permitir que las máquinas procesen el lenguaje natural de manera que sea útil y efectiva para interactuar con las personas o extraer conocimiento a partir de textos.
Tareas en NLP
Algunas de las tareas básicas en NLP que vamos a ver en esta presentación son:
Generación de texto.
Clasificación de texto.
Traducción automática.
Antes de entrar con NLP, vamos a ver algunas técnicas relacionadas.
Objetivos de aprendizaje
Resumir las tareas principales del Procesamiento del Lenguaje Natural.
Interpretar el fundamento de los Autoencoders.
Argumentar cómo se construye un Embedding con la técnica de los Autoencoders.
Construir o adaptar un Embedding.
Razonar cómo funcionan las redes recurrentes en la tarea de generación de texto.
Construir o adaptar una red recurrente para la generación de texto.
Objetivos de aprendizaje
Razonar cómo funciona una red neuronal recurrente para la tarea de clasificación de texto.
Construir o adaptar una red recurrente para la clasificación de texto.
Razonar cómo funciona una red neuronal recurrente para la tarea de traducción automática.
Construir o adaptar una red recurrente para traducción automática.
Razonar cómo funciona la arquitectura Transformer.
Referencias
Hands-on machine learning, Aurélien Géron.
Deep Learning, Ian Goodfellow, Joshua Bengio and Aaron Courbille.
Autoencoders
Introducción
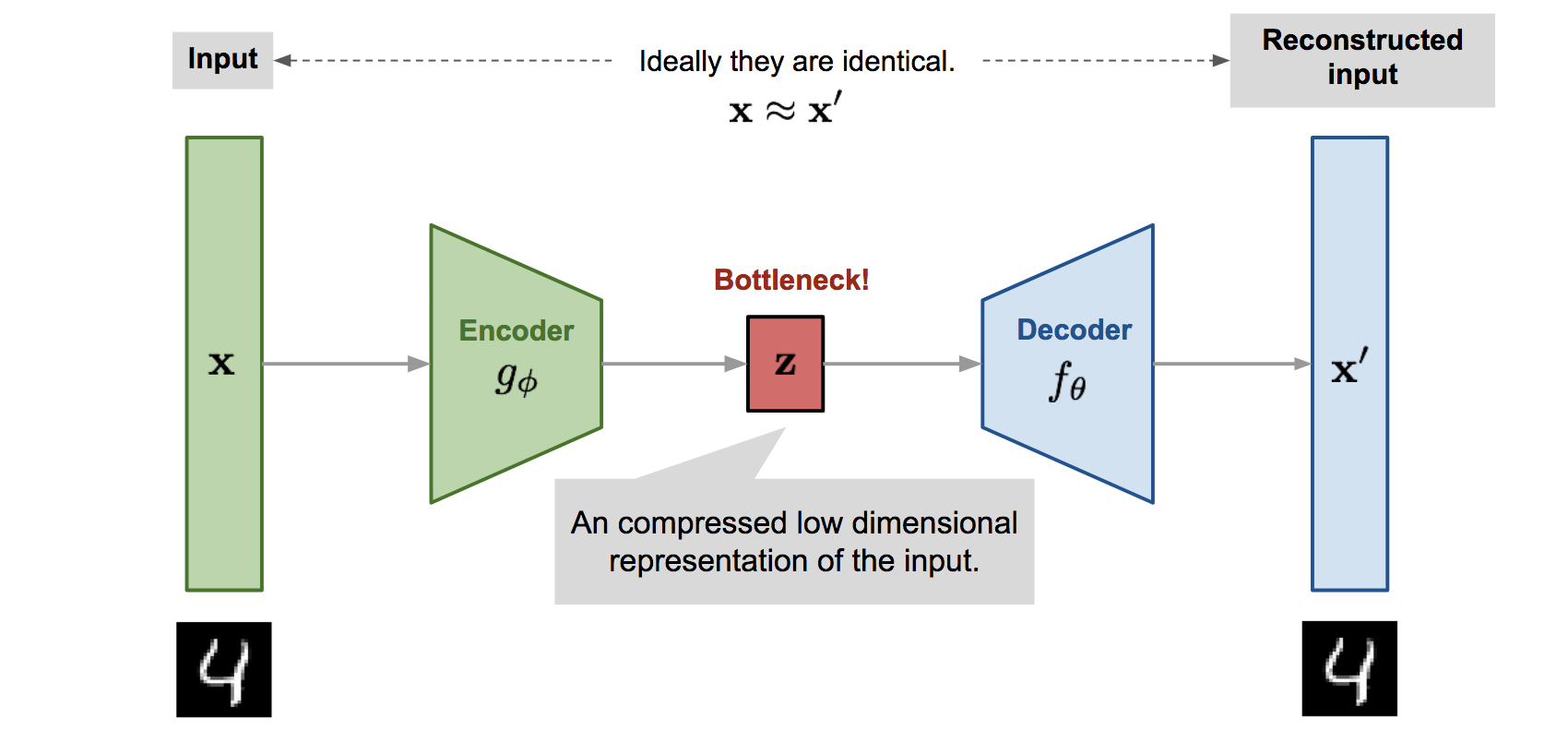
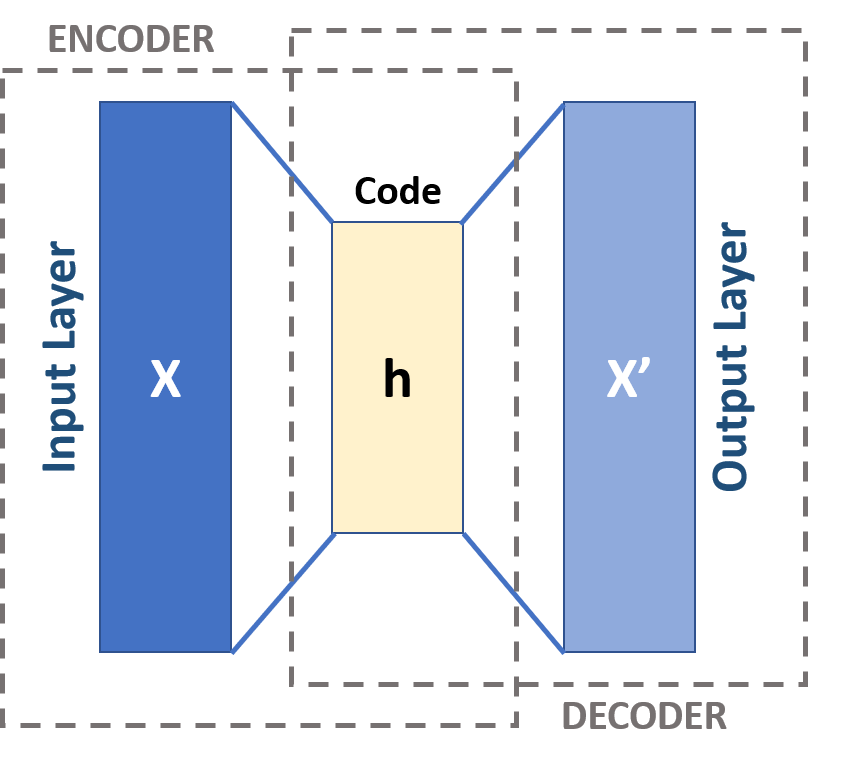
El objetivo de un autoencoder es replicar la entrada en la salida pasando por un espacio de menor dimensión que el espacio de partida:
Introducción
Lo que obtenemos en el espacio intermedio es una representación compacta de la información en el espacio original.
Fíjate en que el entrenamiento es no supervisado, sólo necesitamos muestras de entrenamiento, no es necesario que estén etiquetadas.
Teóricamente, las funciones de entre las capas podrían ser tan potentes que con un espacio intermedio de dimensión 1 pudiésemos reconstruir la imagen original. Seria como si el autoencoder asignase un índice que le permitiese recuperar la imagen inicial,
Afortunadamente, en la práctica, este caso no se da.
Introducción
El trabajo de un autoencoder parece una tarea sencilla, pero tienen muchas aplicaciones:
Detectar anomalías.
Reconstruir imágenes.
Limpiar imágenes.
Detectar anomalías
Entrenamos con un conjunto de muestras sin anomalías. Si al autoencoder llega un dato anómalo la codificación intermedia será incapaz de reconstruir el dato a la salida (gran diferencia entre entrada y salida), y es dato lo podemos considerar anómalo.
Reconstruir imágenes
A partir de una imagen donde falta información, reconstruirla.
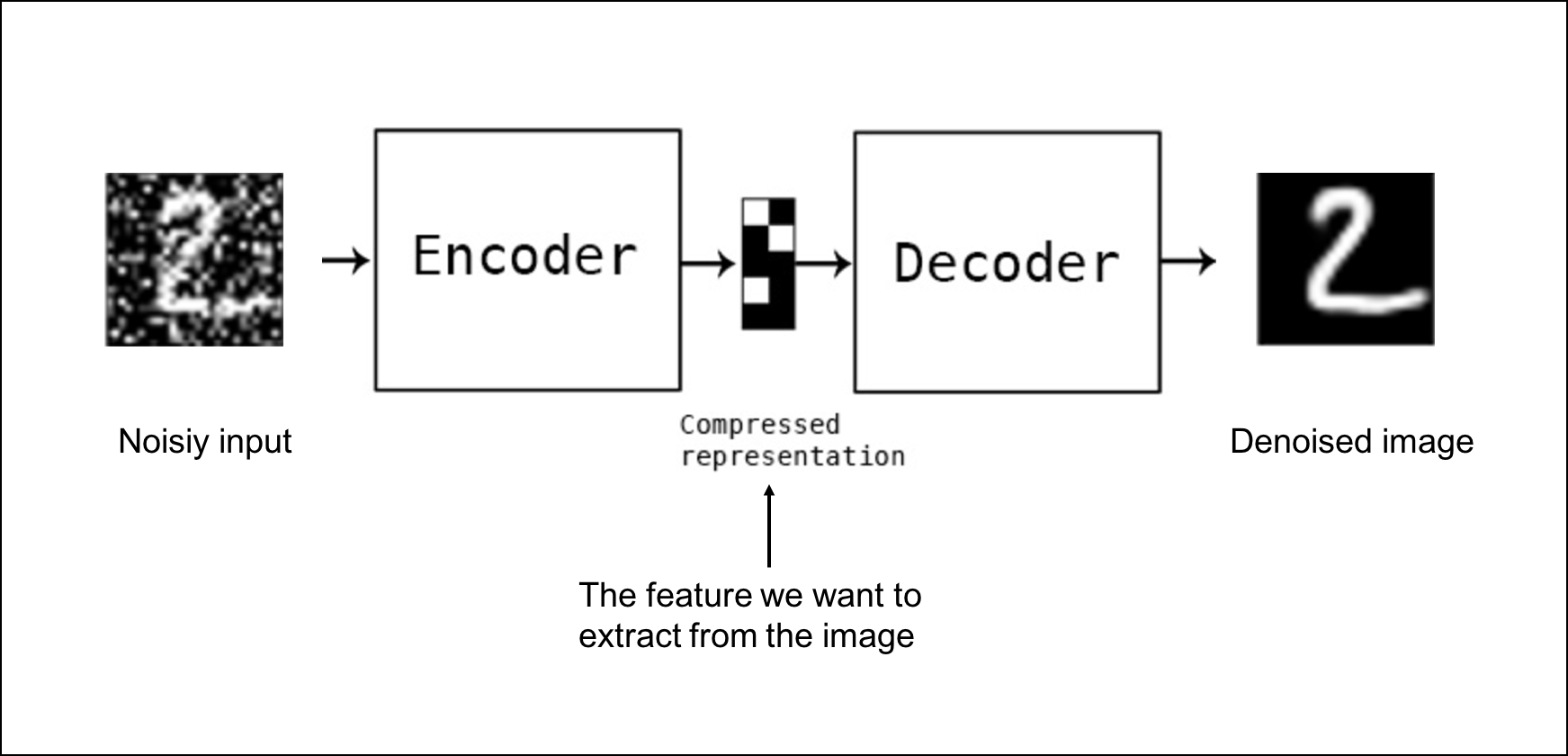
Limpiar imágenes
Limpiar imágenes con ruido.
Embeddings
Introducción
La representación de palabras en un ordenador para realizar cálculos no es trivial.
Usualmente, el primer paso suele ser trabajar con un vocabulario restringido en vez de con todas las palabras posible. La codificación de una palabra que no existe en el vocabulario se sustituye por un código UNKNOWN.
Puso cara de pasmo al oír la noticia
Puso cara de UNKNOWN al oír la noticia
Vectorización de texto
Para la creación del vocabulario a partir de un corpus:
corpus = ["En esta asignatura", "La asignatura que se ha presentado"]vectorizador = tf.keras.layers.TextVectorization()vectorizador.adapt(corpus)print(vectorizador.get_vocabulary())['', '[UNK]', 'asignatura', 'se', 'que', 'presentado', 'la', 'ha', 'esta', 'en']vectorizador(["La asignatura que estamos viendo", "Esta asignatura"])<tf.Tensor: shape=(2, 5), dtype=int64, numpy=array([[6, 2, 4, 1, 1], [8, 2, 0, 0, 0]])>
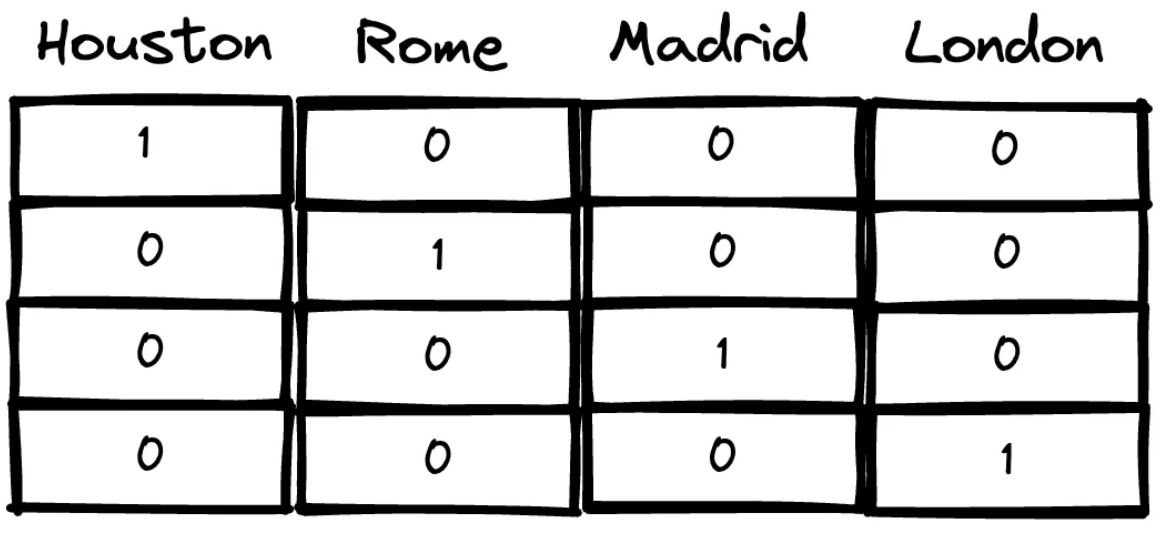
Hay dos códigos especiales: (1) indica que la palabra no pertenece al vocabulario, (0) indica no hay palabra.
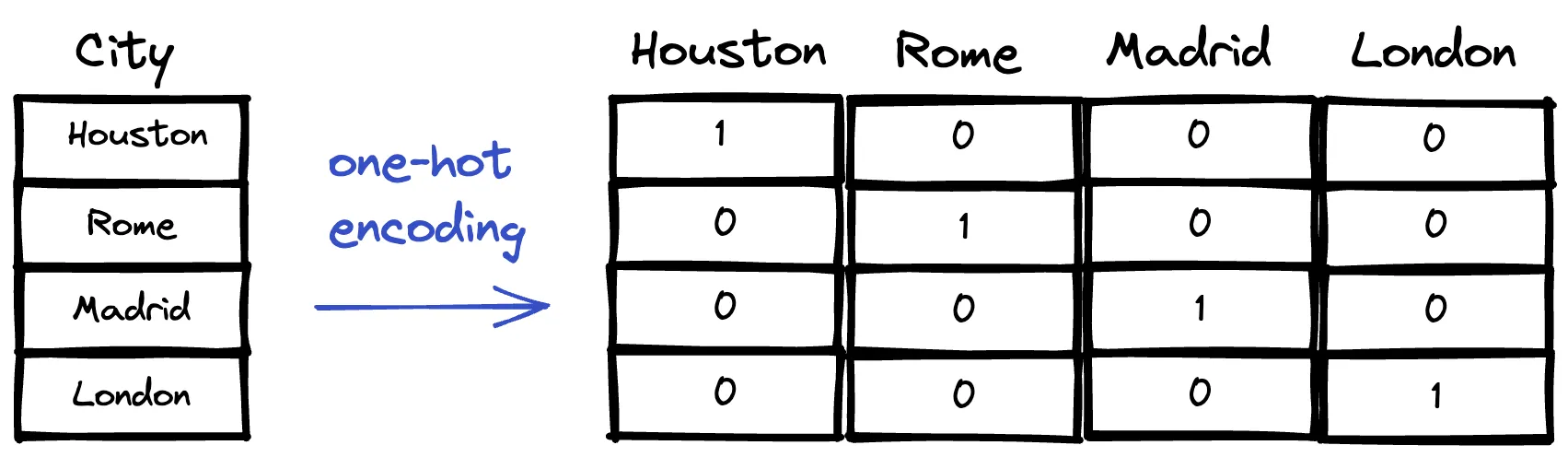
One-hot encoding
Cada palabra se representa por un vector de dimensión igual al número de palabras del vocabulario. Se activa el bit correspondiente a su índice.
Embeddings
Los embeddings son una aplicación de los autoencoders cuando la información con la que estamos trabajando es texto.
La idea base es intentar reducir la dimensionalidad del espacio de partida (número de palabras en el vocabulario), a un espacio que mantenga la información y se más fácil de manejar.
El espacio de partida en esta caso en utilizar codificación one-hot encoding.
Embeddings
Cada uno de los vectores de nuestro espacio one-hot encoding es disperso, muchas de sus componentes están vacías, no aportan información.
Es deseable reducir la dimensión del espacio sin perder información.
Embeddings
En h vamos a tener una representación densa de la información en el espacio one-hot encoding.
Embeddings
En Tensorflow existe una capa para crear embeddings:
Donde tam_vocabulario indica el número de palabras en nuestro vocabulario, y tam_embedding las dimensiones del embedding.
Esta capa se puede entrenar de manera aislada o puede formar parte de una red neuronal.
Word2vec
Word2vec es un embedding muy utilizado, desarrollado por Tomas Mikolov. Se puede entrenar de dos modos:
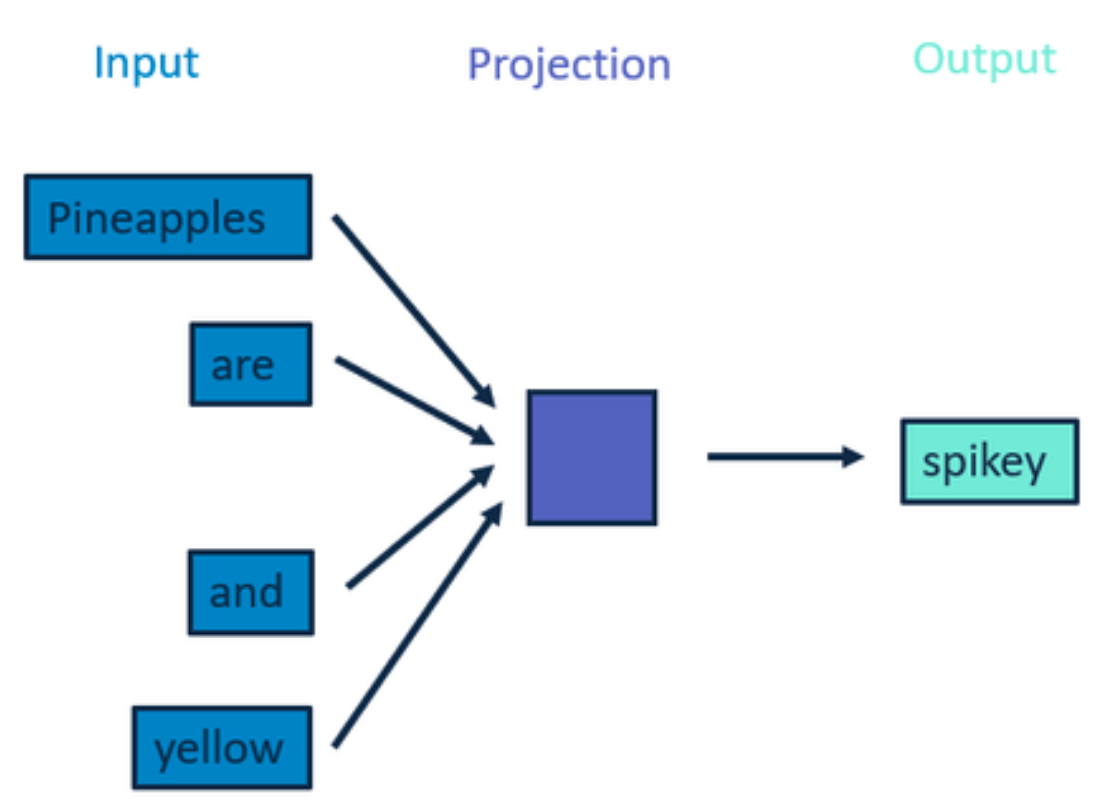
Continuous Bag of Words
Pineapples are spikey and yellow
Word2vec
Word2vec es un embedding muy utilizado, desarrollado por Tomas Mikolov. Se puede entrenar de dos modos:
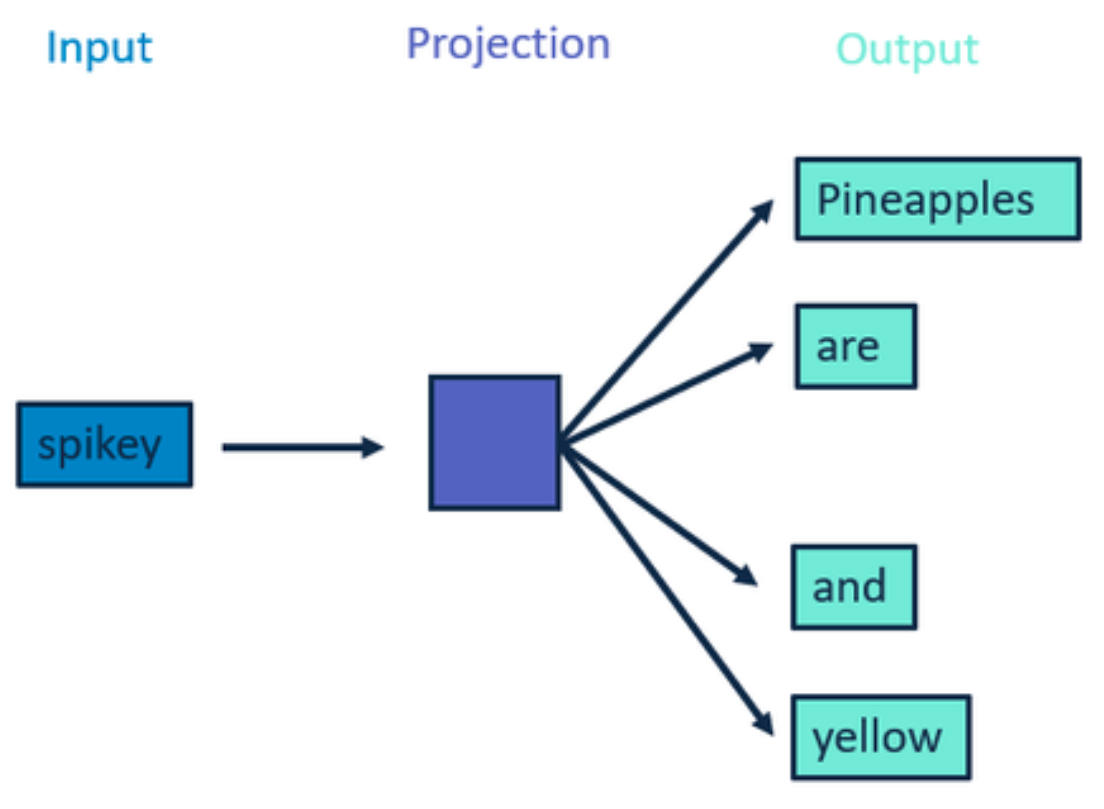
Skip-gram
Pineapples are spikey and yellow
Word2vec
Una primera característica impresionante de este embedding es que, si lo proyectamos a un espacio de 3 dimensiones veremos que conceptos similares se encuentran cerca unos de otros.
Otra característica no menos impresionante, es que podemos hacer operaciones entre los vectores del espacio de Word2vec:
king - male +female = queen (tiene embebida la semántica de realiza)
Spanish - country + Italy = Italian (tiene embebida la semántica de lengua)
dogs - dog + cat = cats (tiene embebido el sentido de pluralidad)
Tareas en NLP
Introducción
Algunas de las tareas típicas en NLP son:
Generación de texto.
Clasificación de texto.
Traducción automática.
Vamos a ver cada una de ellas.
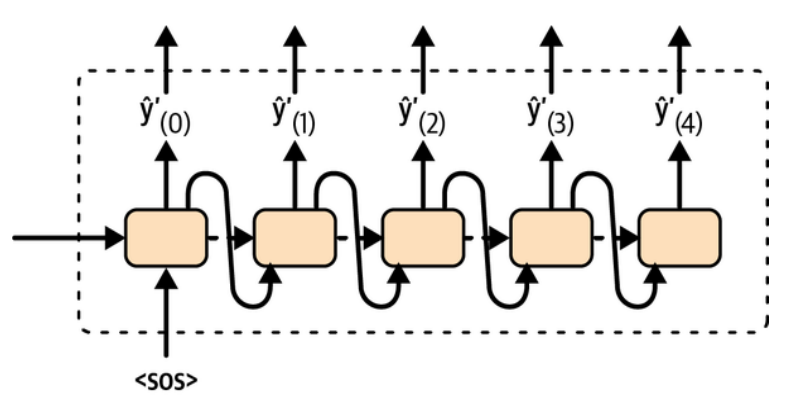
Generación de texto
De manera análoga a la predicción del siguiente valor en secuencias de datos temporales, para generar texto podemos utilizar redes recurrentes (RNN).
Durante el entrenamiento vamos proporcionando a la red secuencias de letras como entrada, y debe predecir la siguiente letra, que se proporciona a la salida.
En este caso podemos utilizar una variación de las RNN, las Gated Recurrent Units (GRU).
Generación de texto
Las celdas (neuronas) GRU (Gated Recurrent Unit) son una mejora de las neuronas LSTM con un rendimiento parecido, pero utilizan menos parámetros, y menos funciones internas para recordar fragmentos de texto.
Generación de texto
Crear una red para generar texto con GRU es relativamente sencillo:
Fíjate en que, en este caso, el embedding se va construyendo en el proceso de entrenamiento de la red.
Generación de texto
Una vez entrenada la red, si le proporcionamos un texto inicial de partida, la red irá añadiendo carácter a carácter hasta alcanzar el carácter especial final.
El estilo del texto generado coincidirá con el del texto utilizado para entrenar la red.
Además, podemos hacer transfer learning, si tenemos una red entrenada, podemos reentrenarla utilizando la misma técnica que empleamos con redes convolucionales:
Generación de texto
Utilizar una arquitectura inicial ya entrenada.
Eliminar las capas más cercanas a la salida y sustituirlas por nuevas capas adaptadas a nuestro problema.
Durante la fase de entrenamiento:
Congelar los pesos de las capas preexistentes.
Entrenar durante unas épocas hasta que la precisión sobre el conjunto de validación se estabilice.
Descongelar todas las capas y entrenar hasta conseguir una buena precisión.
Clasificación de texto
Análisis de sentimientos
Identificación de idiomas
Etiquetado de temas.
Clasificación de texto
Supongamos que queremos clasificar textos como positivos, negativos o neutros.
En el conjunto de entrenamiento, o todos los textos tienen el mismo número de palabras.
Clasificación de texto
Podemos resolverlo insertando una marca especial que indique huecos, donde se esperan palabras.
Pero esto no dará buenos resultados durante el proceso de entrenamiento.
Una mejor solución es indicar a la red que las marcas de hueco no sean tenidas en cuenta durante el proceso de entrenamiento.
De igual modo, los huecos tampoco se tendrán en cuenta en el proceso de clasificación.
Clasificación de texto
Para construir la red que analiza sentimientos, primero construimos la capa de vectorización, ahora estamos trabajando con palabras, e inicialmente no sabemos cuantas palabras tiene nuestro corpus:
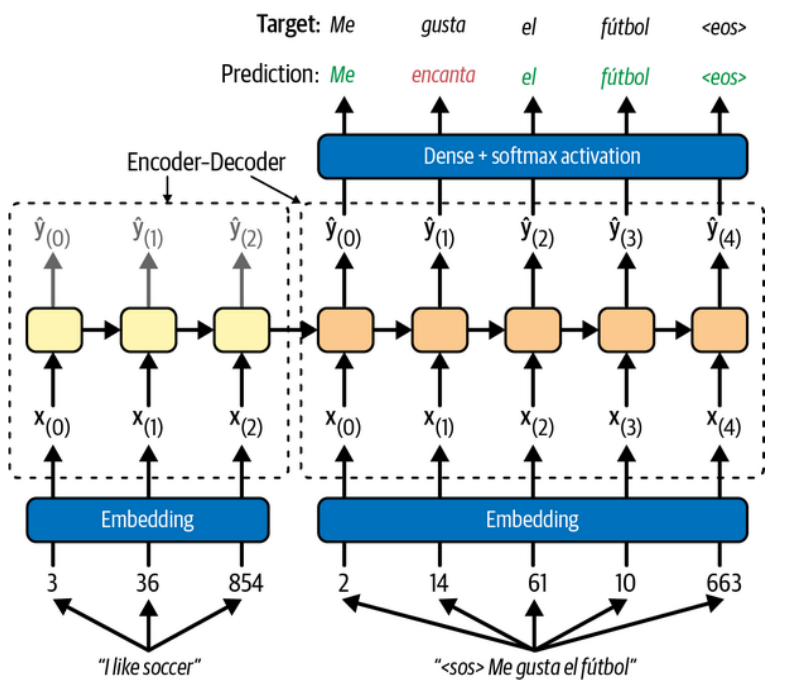
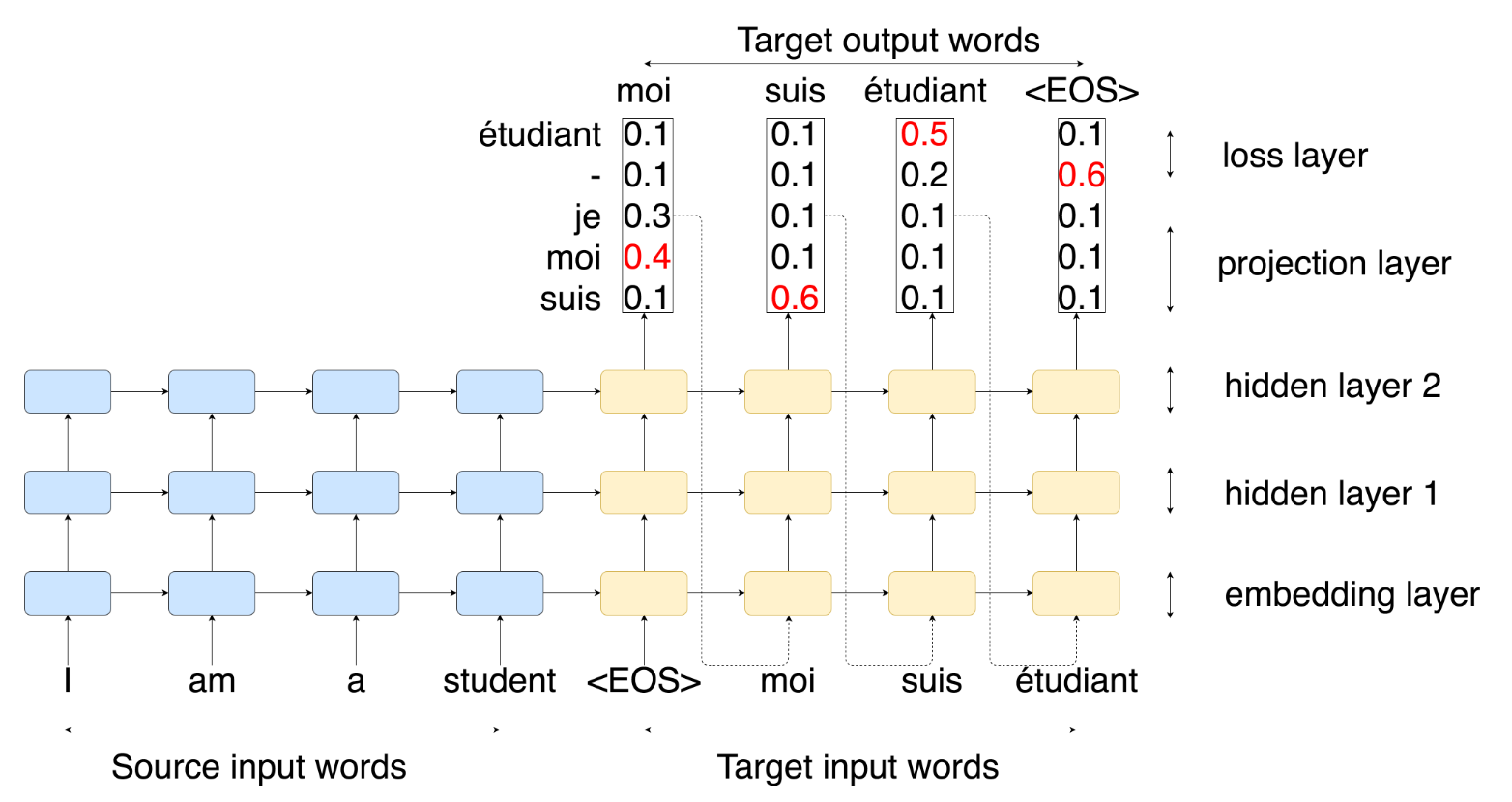
Las redes recurrentes almacenan memoria que es útil para tareas de traducción de textos, ya que es importante guardar el contexto de las palabras en la traducción.
Traducción automática
Durante la fase de entrenamiento.
Traducción automática
Durante la fase de traducción.
Traducción automática
Durante la fase de traducción.
Traducción automática
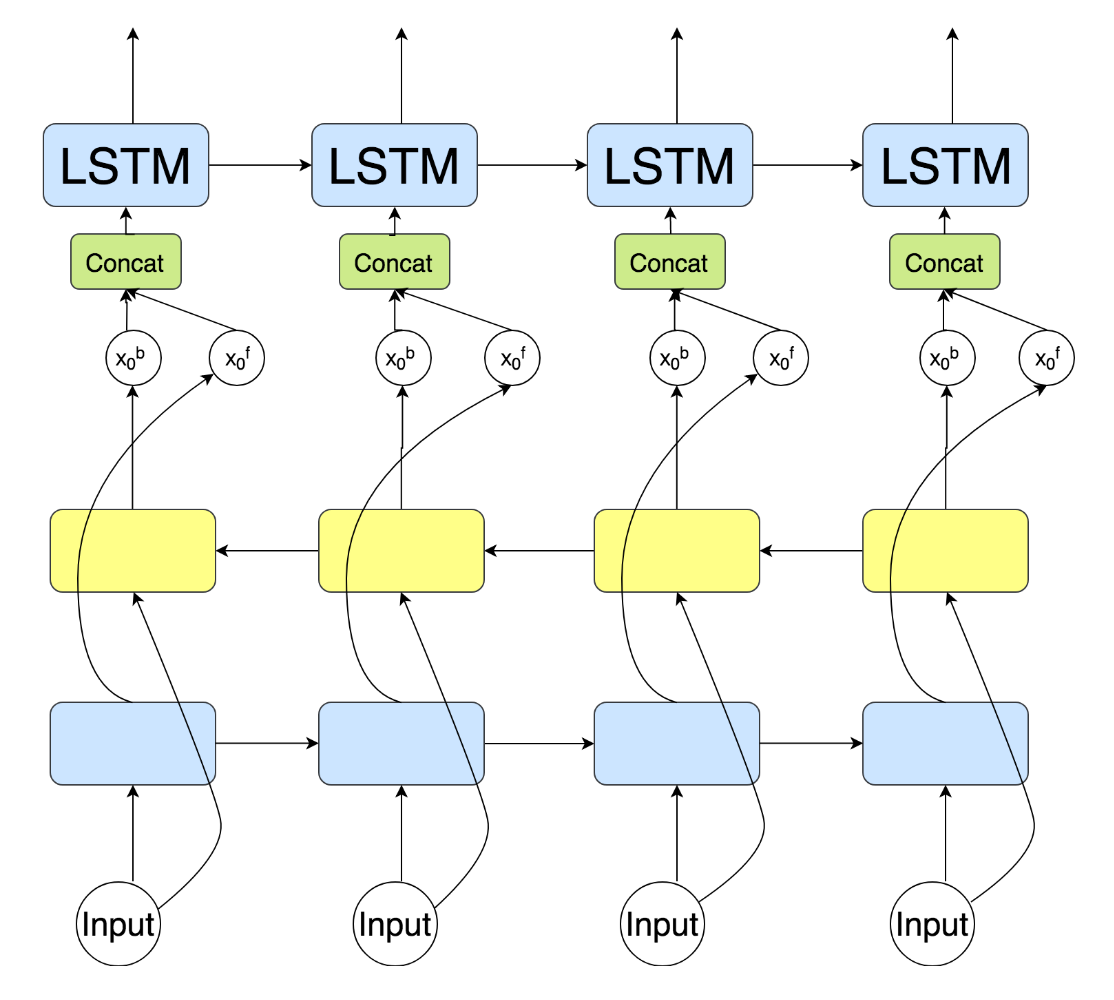
Una mejora de la arquitectura anterior son las redes bidireccionales:
En este caso, la información del estado oculto se transmite en dos direcciones, con lo que el contexto se amplia hacia adelante en la secuencia, y también hacia atrás.
Transformers
Los transformers son una vuelta de tuerca al concepto de mantener la información entre partes de la frase cuando se analiza.
En las redes recurrentes bidireccionales, las posibles relaciones fluyen tanto hacia adelante en la frase como hacia atrás, en el proceso de entrenamiento.
Los transformers utilizan el concepto de atención, que enmascara las partes de la frase que son de interés para la palabra que se está traduciendo en cada momento.
Transformers
Este es el mecanismo de atención tal y como se presenta en el artículo original
Los dos componentes interesante son los bloques de atención (Attention).
Transformers
La parte novedosa es utilizar máscaras para que la red encuentre relación entre las partes del texto aunque estas se encuentren alejadas entre sí dentro de la misma frase.
Transformers
Los Transformers son una de las tecnologías más avanzada para tareas de NLP.
Si te interesa este tema, la página web de referencia es Hugging Face, donde podrás encontrar una buena cantidad de modelos pre-entrenados y mucha información sobre NLP.
Otra web muy útil es la de Somos NLP que une a la comunidad de NLP en español.
Hugging Face
Hugging Face, entre otras muchas cosas, es un repositorio de LLM listos para usar o adaptar en tus aplicaciones.
Su uso básico es muy sencillo.
Primero tendremos que instalar la versión de keras con la que trabaja los transformers de Hugging Face.
micromamba install tf-keras
Y cargamos la biblioteca:
from transformers import pipeline
Hugging Face
Si lo que queremos hacer es clasificación de textos, lo primero es encontrar un modelo entrenado para ello y en español.
Luego, creamos un pipeline indicando la tarea y el modelo.
nombre_modelo ="UMUTeam/roberta-spanish-sentiment-analysis"clasificador = pipeline("sentiment-analysis", model=nombre_modelo)clasificacion = clasificador("No me gusta comer fuera de casa")print(clasificacion)
resumidor = pipeline("summarization")resumen = resumidor( """ En una economía tan estacional como la española, a noser que haya eventos disruptivos como una pandemia o un colapso como el de2008, el comportamiento de la afiliación a la Seguridad Social y del paroregistrado riman cada mes. Y noviembre, con la temporada turística veraniegacompletamente agotada y a la espera de la Navidad, no suele ser un buen mespara el mercado laboral. Así, España perdió en noviembre 30.050 empleos, hastadejar la afiliación media en 21.302.463 trabajadores, el mayor bajón en elundécimo mes desde 2019. El retroceso se centra en la hostelería, un sector enel que se perdieron 120.000 empleos respecto a octubre, lo que también se notaen la desagregación por territorios: la ocupación solo cae con fuerza enBaleares, una región de monocultivo turístico. Los datos son algo mejores enparo registrado, con un retroceso de 16.036 personas. Pero es una caída leve,peor que la de los tres últimos años, de la mano de un dato positivo: el totalde parados en noviembre es el menor desde 2007, antes de la Gran Recesión. Enla misma línea, la cifra de ocupados es la más alta que se haya registradonunca en un mes de noviembre. """)
Hugging Face
Y este es el resultado del resumen:
[{'summary_text':' España perdió en noviembre 30.050 empleos, hastadejar la afiliación media en 21.302.463 trabajadores . El retroceso se centraen la hostelería, un sector en el que se perdieron 120,000 empleo a octubre.'}]
Como puedes ver, bastante bueno.
Otras tareas en NLP
Hay otras muchas tareas dentro del campo de NLP:
Respuestas a preguntas.
Resumidores de texto.
Texto a voz y voz a texto.
Etiquetado de partes del discurso.
Sólo por mencionar algunas.
Resumen
El procesamiento de lenguaje natural es una disciplina muy amplia y con gran tradición dentro de la inteligencia artificial.
Hemos visto algunas de las piezas básicas para trabajar con NLP, como los embeddings.
Hemos visto como las redes recurrentes son muy buenas para algunas tareas típicas dentro de NLP, como la generación de textos, la clasificación y la traducción.
Actualmente, los transformers son la arquitectura con un mejor rendimiento en tareas de NLP.
Hugging Face ofrece una gran cantidad de modelo entrenados listos para ser utilizados, o como base para crear nuestros propios modelos.