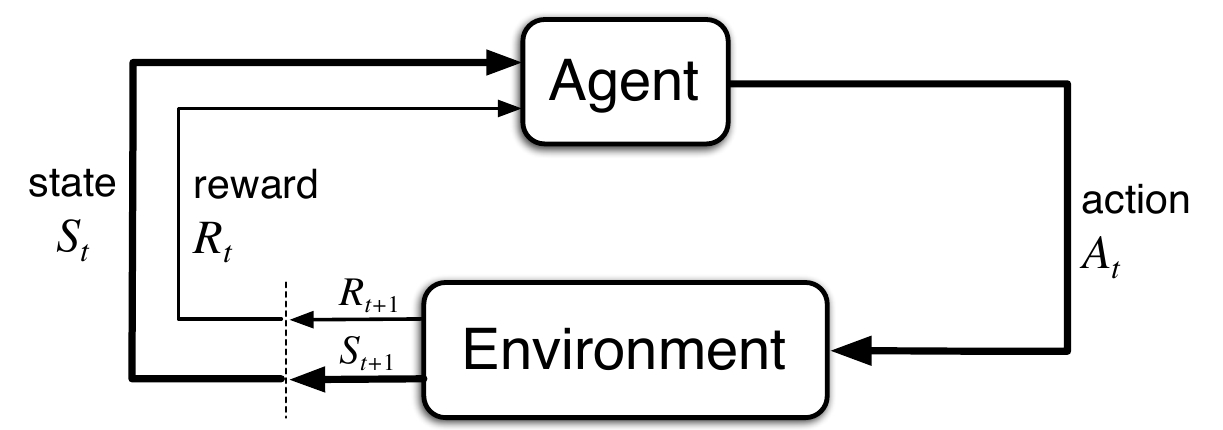
Durante el curso, hemos visto algoritmos de aprendizaje automático que se basan en un conjunto de datos de entrenamiento para construir un modelo.
En el caso del aprendizaje por refuerzo no existe ningún conjunto de datos con el que construir el modelo, en vez de ello, operamos en un entorno que nos devuelve una recompensa dependiendo de la acción que realicemos y el estado en el que nos encontremos.
Son necesarios nuevos algoritmos para encontrar las soluciones dentro de este nuevo paradigma.
Objetivos de aprendizaje
Interpretar cuales son las características particulares del aprendizaje automático.
Resumir los conceptos de agente, estado, acción y recompensa.
Conectar cada uno de los conceptos anteriores con el proceso de aprendizaje.
Construir una solución utilizando el algoritmo Q-learning.
Objetivos de aprendizaje
Argumentar la utilidad del descuento.
Interpretar el dilema explotación frente a exploración.
Argumentar la utilidad del parámetro \(\epsilon\).
En el aprendizaje supervisado construimos un modelo con datos y valores de salida. Nuestro modelo nos dará un nueva salida para cada nuevo dato.
En aprendizaje no supervisado construimos un modelo sólo con datos, y el modelo aprende a identificar las similitudes entre los datos.
Introducción
En aprendizaje por refuerzo tenemos estados (dentro de un entorno), acciones (ejecutadas por un agente) y recompensas, y el objetivo es maximizar la recompensa global tomando las mejores acciones en cada uno de los estados por los que vamos pasando.
Introducción
Ejemplos del mundo real: juegos, robótica, optimización.
Un detalle importante: observa que el entorno puede cambiar, si el agente es un jugador virtual de ajedrez, a cada movimiento del agente le sigue un movimiento del contrario.
Agente, Acción, Estado y Recompensa
Si el conjunto de estados, acciones y recompensas es finito, se conoce el estado actual y la acción elegida, entonces, se puede calcular la probabilidad del siguiente estado y la recompensa obtenida.
Con la condición: \(\sum\limits_{s' \in S} \sum\limits_{r \in R}^{} p(s',r|s,a) = 1\)
A esta elaboración matemática se la llama procesos de decisión de Markov.
Agente, Acción, Estado y Recompensa
Ejemplos de agente pueden ser:
Un coche autónomo.
Un robot en un entorno industrial.
Un dron.
Un jugador virtual de go o ajedrez.
Un personaje en un video juego.
Episodios y Ganancia
En casos como los de un coche autónomo, o un jugador virtual existe uno, o varios, estados finales. Un coche lleva a los pasajeros del punto de recogida al punto de entrega; un jugador virtual gana o pierde una partida, a este concepto lo llamaremos episodio.
En esta caso resulta sencillo definir el concepto de Ganancia a futuro como la suma de las recompensas que obtiene el agente durante el episodio a partir de un cierto instante y hacia adelante:
\[
G_t = R_{t+1} + R_{t+2} + ... + R_T
\]
Donde \(T\) es el tiempo final del episodio.
Episodios y Ganancia
Hay otros casos, como el de un robot en un ambiente industrial, donde no podemos identificar episodios, el agente está realizando de modo continuo acciones y la secuencia de acciones nunca acaba.
En este caso, para acotar la ganancia para que no crezca hacia el infinito, se introduce el concepto de factor de descuento, que es una especie de decaimiento exponencial de la recompensa a futuro.
Donde \(\alpha\) es la tasa de aprendizaje y \(\gamma\) es el factor de descuento.
La función \(Q(s,a)\) es una medida de lo bueno que es estar en el estado \(s\), y realizar la acción \(a\); mide la calidad (Q-uality) de la pareja estado-acción.
\(\gamma \max_{a \in A} Q(S_{t+1},a) \rightarrow\) mejor estado que se puede conseguir al realizar una acción \(a \in A\) (con descuento).
\(R_{t+1} \rightarrow\) recompensa inmediata al realizar la acción \(a \in A\).
Ejemplo
En el estado mostrado (14), la mejor acción que puede tomar el elfo es moverse hacia la derecha, por lo que la calidad (Q) de la pareja (estado=14, acción=derecha) se incrementa.
A esta técnica se le llama Q-learning \(\epsilon\) - voraz
El valor inicial de \(\epsilon\) puede ser \(1\) y decaer en cada episodio de aprendizaje con alguna tasa \(\epsilon\)-decay \(=0.00001\).
Al principio la política es de exploración, y cuando la tabla Q ya contiene algunos valores, \(\epsilon\) ha decaído de manera que se pasa a la fase de explotación.
Función Q en espacios finitos
Con esta mejora, el algoritmo ya es capaz de aprender, y encontrar la solución:
Fíjate en que no hay una única solución posible ya que la fase de exploración es estocástica.
Veamos ahora cómo podemos tratar el caso de entornos con espacios de estados continuo.
Función Q en espacios continuos
Hay casos en los que el espacio de estados no es continuo.
Cartpole: Hay que mantener el bastón en la vertical, sin que se caiga.
El espacio de estado está formado por la posición de la base, su velocidad, el ángulo que forma el bastón con la vertical, y la velocidad angular.
Todas las variables de este espacio son continuas.
¿Cómo procedemos?
Función Q en espacios continuos
Discretizamos el espacio, convertimos las variables continuas en discreta sobre un número suficiente de valores posibles (densidad).
Y, a partir de este momento, procedemos de igual forma que lo hemos hecho en el caso discreto.
Detalle importante, la matriz Q en este caso tiene 10 x 10 x 10 x 10 = 10.000 posiciones.
Función Q en espacios continuos
Cuando el espacio de estados es muy grande, la aproximación con tablas Q no se puede aplicar.
Pero, podemos aplicar redes neuronales para ayudar en la resolución.
Resumen
Resumen
El aprendizaje por refuerzo no parte de un conjunto de datos de entrenamiento.
Los conceptos clave son el agente, los estados, las acciones y las recompensas.
El objetivo de los algoritmos de aprendizaje automático es maximizar la recompensa a futuro.
Resumen
Un algoritmo que se aproxima al óptimo del máximo de recompensa a futuro es el algoritmo Q-learning.
Q-learning tiene una aplicación directa en el caso de entornos discretos, pero si los queremos aplicar a entornos continuos, debemos discretizar los espacios de estados.